- 分散分析の等分散性と正規性はデータ数が同じであればそれほど厳密に考えることはない.
- 分散分析でのF検定ではF比の値が1因子の水準間に有意差のあること,すなわち,「水準間分散>水準内分散」が仮定される片側検定であるが両側仮設と同等の考えて良い.
5.3. 多標本の検定と推定の仕方.
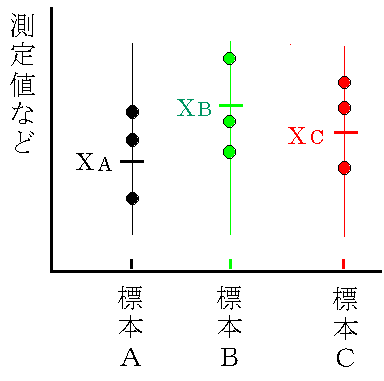
3つ以上の標本間でその平均値の差の検定を行うとき、2つの標本を一対として個々に
t検定「5.2. 2標本の検定と推定の仕方(5.2. 平均値のとき)」を行っているのが、
医学などでのt検定でときどき見受けられます。
これは、例えばA・B・Cの標本において、医学的な経験ないし知識によってAとB、あるいはBとCの平均値に有意な差のあることが検定以前に予想できる場合の限って使用すべきでしょう。
この様な検定は片側仮説に対する探索的な検定であって、その有意性を確認するだけのために用いるものです。
もし、探索的な検定でなければ「分散分析」のF検定の適用を考えるべきです。ここでは分散分析の手法として、
①多標本での「対応のない平均値の差の検定」として、1元配置分散分析。
②多標本での「対応のある平均値の差の検定」として、2元配置分散分析。
について説明します。
なお、分散分析では等分散性と正規性の仮定のもとで検定を行うので、その仮定が困難なものは「ノンパラメトリック検定」を適用するようにします。
注釈表示
5.3.1 対応のないとき(1元配置分散分析)
2つの標本間における平均値の差の検定ではt検定を用いました。3つ以上のパラメトリック検定では1元配置分散分析を用いて検定します。
[一般形式]
[検定の手順]
①検定の問題を明かにする.
「標本間の平均値に差があるか?」
②仮説の設定を行う.
帰無仮設(H0):μ1=μ2=・・・=μk
対立仮設(H1):μ1≠μ2≠・・・≠μk
注釈表示
③危険率(100α%)を設定する.
片側検定の有意水準:α
④検定統計量(FA)を計算する.
多群のデータを
k=標本の数(水準数)
ni=各水準のデータの個数
N=全データの個数
Ⅹij=データ
T=全データの合計
TAi=各水準のデータの合計(i=1,2,・・・,k : j=1,2,・・・,ni)とするとき,1元配置分散分析は表28の様な記号で表わされます.
| 因子(k水準) | 1.....2..・・ .j...・・...n | 計 |
| A1 | X11 X12 ・・ X1j ・・ X1n1 | TA1 |
| A2 | X21 X22 ・・ X2j ・・ X2n2 | TA2 |
| : | : | : |
| Ai | Xi1 Xi2 ・・ Xij ・・ Xini | TAi |
| : | : | : |
| Ak | Xk1 Xk2 ・・ Xkj ・・ Xknk | TAk |
| 総和 | N=n1+n2+・・+nk | T |
表28 から各平方和(変動)は,次により求めます.
全平方和(全変動) : ST=∑∑X-T/N
級間平方和(級間変動):SA=∑T/n-T/N
誤差平方和(級内変動):SE=ST-SA
これらの平方和を 表29 の1元配置分散分析表にまとめます.
| 要因 | 平方和(S) | 自由度(DF) | 分散(V) | F比 |
| 因子(A) 誤差(E) | SA SE | DFA=k-1 DFE=N-k | VA=SA/DFA VE=SE/DFE | FA=VA/VE |
| 全体(T) | ST | DFT=N-1 | .. | .. |
表29の1元配置分散分析表から検定統計量はF比欄のFAとなります.
⑤統計的判定を行う.
FA<F(DFA,DFE,α)ならば,「危険率100α%で有意な差がない」
FA≧F(DFA,DFE,α)ならば,「危険率100α%で有意な差がある」
なお,F(DFA,DFE,α)は表計算ソフト(エクセル)から求めます.
求め方は「例題24」を参考にして下さい。
⑥100(1-α)%の信頼限界を求める.
上限値:
TAi/ni+t(DF,α/2)×SQRT(VE/n)
下限値:
TAi/ni-t(DF,α/2)×SQRT(VE/n)
但し,各水準の分散が等しいときに限り求めることができます.
[例題24]
収縮期血圧について3標本(A・B・C)の年代別における平均値と標準偏差が与えられているとき,そのデータをもとに分散分析を行ってみましょう.
各標本(水準)での平均値(Xbar),標準偏差(s),データの個数(n)は,次の通りです.
XAbar=127.4 ,sA=17.2 ,nA=50
XBbar=130.3 ,sB=19.7 ,nB=50
XCbar=143.0 ,sC=26.8 ,nC=50
例題では各標本(水準)での平均値(Xibar)と標準偏差(si)しか与えられていません.
しかし,分散分析でのF検定は級内変動に対する級間変動の割合を示すものですので,
全標本での全変動は,
∑∑(Xij-Xbar)2=∑∑(Xij-Xibar)2+∑ni(Xibar-Xbar)2
で表されます.ここで、
∑∑(Xij-Xibar)2を第1項、
∑ni(Xibar-Xbar)2を第2項
とするなら、
第1項は級内変動(Si)であり,Si=(ni-1)×si2に等しいものです.
したがって,例題での各標本(水準)での平均値(Xibar)および標準偏差(si)から,
総平均(Xbar)は,
Xbar=∑niXbar/N
(N=nA+nB+nC)
から求められます.
以下に例題での計算手順を示します.
総平均(Xbar):
Xbar=50×(127.4+130.3+143)/150=133.57
級内変動(SE):
SA=(nA-1)sA2=(50-1)×17.2^2=14496.16
SB=(nB-1)sB2=(50-1)×19.7^2=19016.41
SC=(nC-1)sC2=(50-1)×26.8^2=35193.76
計 SE=68706.33
級間変動(SA):
SA=50×(127.4-133.57)^2=1903.445
SB=50×(130.3-133.57)^2= 534.645
SC=50×(143.0-133.57)^2=4446.245
計 S=6884.335
これらを1元配置分散分析表にまとめると表30 のようになります.
| 要因 | 平方和(S) | 自由度(DF) | 分散(V) | F比 |
| 因子(A) 誤差(E) | SA=6884.335 SE=68706.33 | DFA=3-1 DFE=150-3 | VA=3442.17 VE=467.39 | FA=7.365 |
| 全体(T) | ST=75590.665 | DFT=150-1 | .. | .. |
ここで,F分布の上側パーセント点は表計算ソフト・エクセル(関数式)から,
FA(DFA,DFE,α)=F(2,147,0.05)=3.0576
ですので,
FA=7.365>F(2,147,0.05)= 3.0576(危険率 5%)
から,各標本での平均値に有意な差があると云えます.
すなわち,年代(3標本)によって平均値の異なる標本(水準)があると判断されます.
なお,標本(A)と標本(B)が等分散とすれば,その95%信頼限界は次のようになります.
標本(A):
XAbar±t(DFE,0.05/2)・SQRT(VE/nA)=127.4±1.9762×SQRT(467.39/50)=127.4±6.042
標本(B)
XBbar±t(DFE,0.05/2)・SQRT(V/nB)=130.3±1.9762×SQRT(467.39/50)=130.3±6.042
なお,t(DFE,0.05/2)は表計算ソフト・エクセル(関数式)から求めます.
以上は表計算ソフト「エクセル」を用いて計算することが出来ます。
[例題25]気管支喘息患者の病態別の血清IgE値(IU/L)を次に示します.
| アトピー型 | 混合型 | 感染型 |
| 850 | 840 | 260 |
| 600 | 540 | 200 |
| 710 | 560 | 100 |
| 900 | 400 | 210 |
| 550 | 830 | 300 |
ここで,
標本の数:k =3
各データの個数(水準数):ni=5,5,5(i=1,2,3)
総データの個数:N=5+5+5=15
です.以上から,
表計算ソフト(エクセル)の「分析ツール」(Sheet名「分析ツール」)を用いた方法を次に示します。
「分析ツールによる方法」
「ツール(T)」→「分析ツール(D)」→「分散分析:1元配置」
以上から,検定統計量(FA)は,
FA=VA/VE=16.67
となります.
ここで,自由度DFA=k-1= 2 ,DFE=N-k= 12 ,有意水準 α=0.05 に対するF分布のパーセント点は,
F(2,12,0.05)=3.8853 ですので,
F=16.67>F(2,12,0.05)=3.8853(危険率 5%)
から,標本間の平均値に有意な差があると云えます.
誤用を避けるために!
血清IgE 値は非正規分布であることが知られています.一元配置分散分析では正規性、等分散の仮定のもとに検定が行われます。
したがって、血清IgE 値は自然対数変換をおこない正規分布近似とする必要があります。
自然対数変換値による結果は次の通りです.
自然対数変換値
| アトピー型 | 混合型 | 感染型 |
| 6.745 | 6.733 | 5.561 |
| 6.397 | 6.292 | 5.298 |
| 6.565 | 6.328 | 4.605 |
| 6.802 | 5.991 | 5.347 |
| 6.310 | 6.721 | 5.704 |
分散分析表
| 要因 | 自由度 | 平方和 | 平均平方 | F値 | p値 |
| Ln(IgE) | 2 | 4.741 | 2.37 | 21.956 | <0.0001 |
| 誤差 | 12 | 1.296 | 0.108 | ... | ... |
| 全体(修正済み) | 14 | 6.036 | ... | ... | ... |
この様なF検定は級内変動に対する級間変動の割合によって決まるものであり,その有意差を示す標本間を特定するものではありません.
したがって,有意差を示す標本間を特定しなければF検定をした意味がないと云えます.
これについては,次の「5.3.2. 多群関の平均値を比較するとき」で説明しますので,ここでは1元配置分散分析の仕方を知っておいて欲しいと思います.
「注釈」
戻る 次へ 目次へ TOPへ