- 僨乕僞夝愅娐嫬乽R]偼丄擔乆僶乕僕儑儞傾僢僾偝傟偰偄傞偺偱丄偛拲堄偝傟偨偄丅
- 乽R乿偺嵟怴僶乕僕儑儞偵傛偭偰偼僄儔乕偵側傞応崌傕偁傞丅
9.4.2. 庡惉暘夞婣暘愅乮夞婣庡惉暘暘愅乯偺曽朄偵偮偄偰丅
堛妛偲摑寁(55)
(56)搳峞偐傜丅
栚揑曄悢(Y)傪愢柧曄悢(X)偱愢柧偟傛偆偲偡傞側傜廳夞婣儌僨儖傪峫偊傑偡丅偟偐偟丄懡廳嫟慄惈側偳愢柧曄悢娫偺憡娭偑崅偄
乮椺偊偽丄帪宯楍僨乕僞乯偲廳夞婣暘愅傪偍偙側偭偰傕傎偲傫偳栚揑傪壥偨偣側偄偙偲偑偁傝傑偡丅
偙偺條側応崌丄庡惉暘暘愅偺摿惈抣傪愢柧曄悢偲偟偰廳夞婣暘愅傪偍偙側偭偨曽偑椙偝偦偆偱偡丅
椺偊偽丄
昞侾偺僨乕僞偺條側応崌偱偡丅
昞1丗栚揑曄悢偲廬懏曄悢偐傜側傞僨乕僞
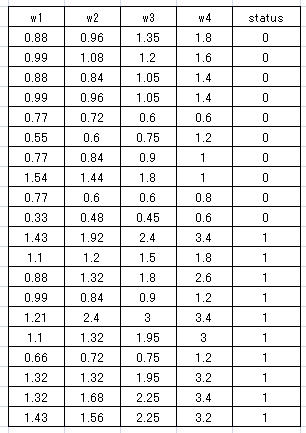
昞1 偺曄悢(status)偼栚揑曄悢偱偁傝丄偙偙偱偼丄嵶朎偲偐旝惗暔偲偐壗傜偐偺寁應抣偺寢壥丄椺偊偽丄
嵶朎敪堢忬懺(good亖侽, poor亖侾)傪丄偦偟偰丄乽w1乣w4乿偼廡扨埵側偳偺帪娫傪昞偟偰偄傑偡丅
摉慠丄寁應帪乽w1乣w4乿娫偵偼崅偄憡娭娭學偑偁傝傑偡丅偙偺僨乕僞偵偮偄偰庡惉暘暘愅傪偍偙側偭偰傒傑偟傚偆丅
庡惉暘暘愅偼摑寁夝愅娐嫬乽R}偱偼丄師偺條偵側傝傑偡丅
dat<- matrix( c(
| 0.88, | 0.96, | 1.35, | 1.8, | 0, |
| 0.99, | 1.08, | 1.20, | 1.6, | 0, |
| 0.88, | 0.84, | 1.05, | 1.4, | 0, |
| 0.99, | 0.96, | 1.05, | 1.4, | 0, |
| 0.77, | 0.72, | 0.60, | 0.6, | 0, |
| 0.55, | 0.60, | 0.75, | 1.2, | 0, |
| 0.77, | 0.84, | 0.90, | 1.0, | 0, |
| 1.54, | 1.44, | 1.80, | 1.0, | 0, |
| 0.77, | 0.60, | 0.60, | 0.8, | 0, |
| 0.33, | 0.48, | 0.45, | 0.6, | 0, |
| 1.43, | 1.92, | 2.40, | 3.4, | 1, |
| 1.10, | 1.20, | 1.50, | 1.8, | 1, |
| 0.88, | 1.32, | 1.80, | 2.6, | 1, |
| 0.99, | 0.84, | 0.90, | 1.2, | 1, |
| 1.21, | 2.40, | 3.00, | 3.4, | 1, |
| 1.10, | 1.32, | 1.95, | 3.0, | 1, |
| 0.66, | 0.72, | 0.75, | 1.2, | 1, |
| 1.32, | 1.32, | 1.95, | 3.2, | 1, |
| 1.32, | 1.68, | 2.25, | 3.4, | 1, |
| 1.43, | 1.56, | 2.25, | 3.2, | 1 |
), ncol=5, nrow=20, byrow=T)
colnames(dat)<- c("w1","w2","w3","w4","status")
dat
dat.pc<- princomp(dat, cor=TRUE)
summary(dat.pc, loadings=TRUE)
round(dat.pc$scores, 2)
biplot(dat.pc)
恾1丂庡惉暘嶶晍恾(biplot)
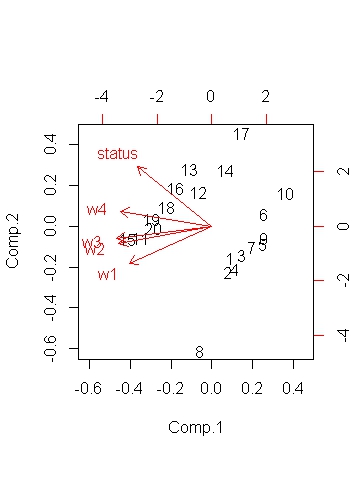
恾侾偱偼柧傜偐偵俀偮偺孮偵暘偐傟偰偍傝摿挜揑側嶶晍恾偱偡丅
庡惉暘夞婣(PCR)偼丄
偙偙偱偺 COMP-1 偺庡惉暘僗僐傾傪愢柧曄悢偲偟偰廳夞婣宆暘愅傪峴偭偨傕偺偱偡丅
偙偙偱偼丄栚揑曄悢(status)偑乽侽乿偲乽侾乿偺俀抣偱偡偺偱丄logistic 夞婣暘愅傪揔梡偟傑偡丅
乽R乿偱偼師偵傛傝幚峴偡傞偙偲偑弌棃傑偡丅
dat<- as.data.frame(dat)
pcr<- princomp ( dat , cor = TRUE )
summary ( pcr , loading=TRUE )
comp.1<- pcr$scores [ , 1 ]
logit.model<- glm ( status ~ comp.1, binomial , data=dat)
summary ( logit.model )
偙偺幚峴寢壥偼昞2 偺條偵側傝傑偡丅
昞2 弌椡寢壥
| Coefficients: | Estimate | Std. Error | z value | Pr(>|z|) | .. |
| (Intercept) | 0.3589 | 0.7959 | 0.451 | 0.6520 | .. |
| comp.1 | -1.5474 | 0.6696 | -2.311 | 0.0208 | * |
---
Signif. codes: 0 乪***乫 0.001 乪**乫 0.01 乪*乫 0.05 乪.乫 0.1 乪 乫 1
栚揑曄悢(status)偲愢柧曄悢(w1乣W4)偺娭學偼戞1庡惉暘僗僐傾乕傪愢柧曄悢偲偟偨 logistic 夞婣儌僨儖偵傛偭偰丄
嵶朎敪堢忬懺 ( good=0 , poor=1 ) 偺梊應傪峴偆傕偺偱偟偨丅
偙偙偱偼丄Logistic 夞婣儌僨儖傊偺摉偰偼傔偱偡偺偱丄偦偺梊應幃偼丄
f(X)=exp ( 兛亄兝X )乛(1亄exp(兛亄兝X ) ) 亖exp ( 0.359亄(亅1.5474)* X )乛( 1亄exp (0.3589亄(亅1.5474)* X 乯
乮乽X乿 偼 comp.1 偺 score 偱偡乯
乽R乿偱偼 fitted ( logit.model ) 偱 梊應抣乮status乯傪媮傔傜傟傑偡丅status 偺敾掕偼乽0.5 埲忋亖侾乿偲偟傑偡丅
捠忢丄廳夞婣宆暘愅偼梊應儌僨儖幃傪悇掕偡傞傕偺偱偡偑丄堛妛偱偼廳夞婣宆儌僨儖偵傛傞枹抦曄悢偺梊應傛傝傕愢柧曄悢偺
摑寁妛揑側桳堄惈傪栚揑偵廳夞婣宆暘愅傪峴偆偙偲偑懡偄傛偆偱偡丅
杮棃偼丄枹抦僒儞僾儖傪夞婣幃偵摉偰偼傔偨偲偒偺梊應偺椙偄儌僨儖傪媮傔傞帠偵偁傝傑偡丅傑偨丄懡廳嫟慄惈偵栤戣偼側偄偐傪
栤偄傑偟偨偑丄PCR 偱偼庡惉暘僗僐傾乕傪愢柧曄悢偲偟偰偍傝丄懳墳偡傞屌桳抣偺崅偄傕偺傪梡偄偰偍傝傑偡偺偱丄
懡廳嫟慄惈傪婥偵偟側偔偰傕椙偄偲尵偆偺偑丄嵟嬤偺夞婣暘愅偺摦岦偱偡丅偟偐偟丄
堛妛偺傛偆偵摑寁妛揑桳堄曄悢偺 select 偑栚揑偺応崌偼丄懡廳嫟慄惈傪柍帇偡傞偙偲偼弌棃傑偣傫丅偙偺條偵丄
庡惉暘僗僐傾乕側偳偺 factor 偵婎偯偔夞婣暘愅偲偟偰偼丄PCR乮Principal Compornent Regression 乯 傗 PLS
( Partial Least squares ) 偑偁傝傑偡丅
愭偺 PCR 偱偼乽R乿偺 princomp 傪梡偄偨僾儘僌儔儉傪徯夘偟傑偟偨偑丄library(pls) 偱偼師偵傛傝暘愅偑弌棃傑偡丅
library(pls)
summary ( pcr ( status~ ., 3 , data = dat ))
summary ( plsr( status~ ., 3 , data = dat ))
乮乽R乿偺僶乕僕儑儞偵拲堄乯
學悢偼師偵傛傝媮傔傞帠偑弌棃傑偡丅
乽PCR 偺學悢乿
p1<- pcr ( status~ ., 3 , data = dat )
round ( p1$coefficients , 3 )
, , 1 comps
....status
w1 0.051
w2 0.095
w3 0.145
w4 0.209
, , 2 comps
....status
w1 -0.093
w2 -0.073
w3 -0.010
w4 0.427
, , 3 comps
....status
w1 0.020
w2 -0.123
w3 -0.039
w4 0.443
乽PLS 偺學悢乿
p2<- plsr ( status~ ., 3 , data = dat )
round ( p2$coefficients , 3 )
, , 1 comps
....status
w1 0.044
w2 0.086
w3 0.134
w4 0.224
, , 2 comps
....status
w1 -0.060
w2 -0.062
w3 -0.048
w4 0.441
, , 3 comps
....status
w1 0.175
w2 0.084
w3 -0.318
w4 0.505
埲忋偺學悢偐傜丄戞1庡惉暘傪梡偄偨廳夞婣宆儌僨儖偼丄
Y pcr亖0.051W1亄0.095W2亄0.145W3亄0.209W4亄(intercept)
Y pls亖0.044W1亄0.086W2亄0.134W3亄0.224W4亄(intercept)
偲側傝丄Y 抣偑乽1乿偵嬤偄偐偳偆偐偱摉偰偼傔偺惓岆傪敾抐偟傑偡丅
偟偐偟丄乽R]偱偼丄fitted() 娭悢偱丄師偵傛傝梊應抣偑摼傜傟傑偡丅
PCR 偺戞1庡惉暘乮 1 comps 乯傪巊梡丅
p1<- pcr ( status~ ., 1 , data = dat )
b1<- coef(p1, ncomp = 1, intercept = TRUE)
round(b1, 3)
round(p1$fitted, 1)
PLS 偺戞1庡惉暘乮 1 comps 乯傪巊梡丅
p2<- plsr ( status~ ., 1 , data = dat )
b2<- coef(p2, ncomp = 1, intercept = TRUE)
round(b2, 3)
round(p2$fitted, 1)
乽拲庍乿
栠傞 師傊 栚師傊 TOP傊